✔️ LCS란?
LCS는 Longest Common Subsequence의 약자로, 번역하면 최장 공통 부분 문자열이라고 할 수 있다.
LCS는 LIS(Longest Increasing Sebsequence, 최장 증가 부분 수열)와 같이
DP(Dynamic Programming)를 기반으로 한다.
부분 문자열이라는 개념에는 Substring이라는 개념과 Subsequence라는 개념이 있다.
Substring은 연속된 부분 문자열을 확인하는 개념이고,
Subsequence는 연속되지 않은 부분 문자열을 찾는 개념이다.
이 둘의 차이점은 연속 여부이다.
예를 들어 ABCDHEF를 봐보자.

최장 공통 문자열(Substring)의 길이는 3, 최장 공통 부분 문자열(Subsequence)의 길이는 5가 나오게 된다.
✔️ LCS(Longest Common Subsequence) 알고리즘 상세 과정
이제 LCS(Longest Common Subsequence) 알고리즘을 어떻게 구현하는지 생각해보자.
ACAYKP와 CAPCAK 이 두 단어를 통해 확인해보자.
먼저, LCS 알고리즘을 구현할 때는 LCS 테이블의 첫번째 행과 첫번째 열을 항상 0으로 맞춰준다.

이제 CAPCAK의 첫번째 단어인 C에 따라 테이블을 채우면 다음과 같다.
여기서 1의 의미는 A까지의 LCS는 0, AC까지의 LCS는 1, ACA까지의 LCS는 1 ... ACAYPK까지의 LCS는 1이라는 뜻이다.
즉, AC까지 LCS가 1이라는 것은 AC와 C에 공통 부분 문자열이 1개 있다는 뜻이다.

다음으로 ACAYKP와 CA를 비교해보자. LCS는 2가 나올 것이다. ACAYKP, CA

ACAYKP와 CAP를 비교했을 때 작성된 테이블은 다음과 같다.
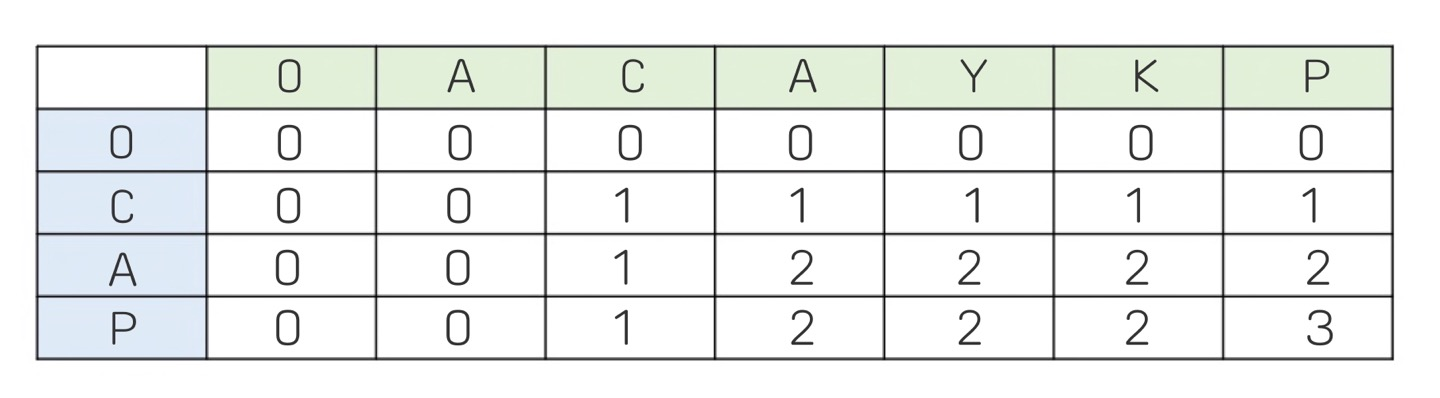
어느 정도 감이 왔겠지만, 정확히 어떤 기준으로 테이블을 채우게 되는 것일까?
💡 현재 서로 다른 문자열일 때는 현재 테이블에 들어갈 수 있는 위쪽, 왼쪽 중 큰 값을 따른다.
💡 현재 서로 같은 문자열일 때는, 현재 테이블에 들어갈 수 있는 대각선(왼쪽 위)의 값 + 1이다.
LCS 구성이 완료된 테이블은 다음과 같다.

✔️ LCS(Longest Common Subsequence) 소스코드
ACAYKP와 CAPCAK를 기준으로 LCS 테이블을 채우기 위해서는 다음과 같이 작성한다.
#include <iostream>
#include <vector>
using namespace std;
int main()
{
string str1 = "ACAYKP";
string str2 = "CAPCAK";
int len1 = str1.length();
int len2 = str2.length();
vector<vector<int>>lcs(len2+1, vector<int>(len1+1, 0));
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
//비교하는 문자가 같은 경우 : 왼쪽 대각선의 값 + 1
if (str1[i-1] == str2[j-1]) lcs[i][j] = lcs[i - 1][j - 1] + 1;
//비교하는 문자가 다른 경우 : 상(위쪽), 좌(왼쪽) 중 큰 값
else lcs[i][j] = max(lcs[i - 1][j], lcs[i][j - 1]);
}
}
cout << "LCS 테이블 : " << endl << endl;
for (int i = 0; i < lcs.size(); i++)
{
for (int j = 0; j < lcs[0].size(); j++)
cout << lcs[i][j] << " ";
cout << endl;
}
cout << endl << "LCS 길이 : " << lcs[len2][len1];
return 0;
}출력 결과
LCS 테이블 :
0 0 0 0 0 0 0
0 0 1 1 1 1 1
0 1 1 1 2 2 2
0 1 2 2 2 3 3
0 1 2 2 2 3 3
0 1 2 2 2 3 4
0 1 2 3 3 3 4
LCS 길이 : 4
Reference